New Applications Driving Higher Bandwidths – Part 1

TEF21 Panel Q&A – Part 1![]()
Nathan Tracy, Ethernet Alliance Board Member and TE Connectivity
Brad Booth, Microsoft
Tad Hofmeister, Google
Rob Stone, Facebook
Addressing Emerging Network Challenges
According to Cisco’s Annual Internet Report (2018-2023), the number of devices and connections are growing faster than the world’s population. Compounded by the meteoric rise of higher resolution video – expected to hit 66 percent by 2023 – along with surging M2M connections, Wi-Fi’s ongoing expansion, and increasing mobility among Internet users, the impact to the network is significant.
Day Two of TEF21: The Road Ahead conference focused on today’s explosive application space as a driver for higher speeds. In New Applications Driving Higher Bandwidths, moderator and Ethernet Alliance Board Member Nathan Tracy of TE Connectivity, and panelists Brad Booth of Microsoft (Paradigm shift in Network Topologies); Facebook ‘s Rob Stone (Co-packaged Optics for Datacenters); and Tad Hofmeister of Google (OIF considerations for beyond 400ZR) discussed how their organizations plan to address emerging network challenges wrought by today’s mounting bandwidth demands.
At the presentation’s conclusion, the audience engaged with panelists on numerous questions about technology developments needed to address escalating speed and bandwidth requirements. Their insightful responses are captured 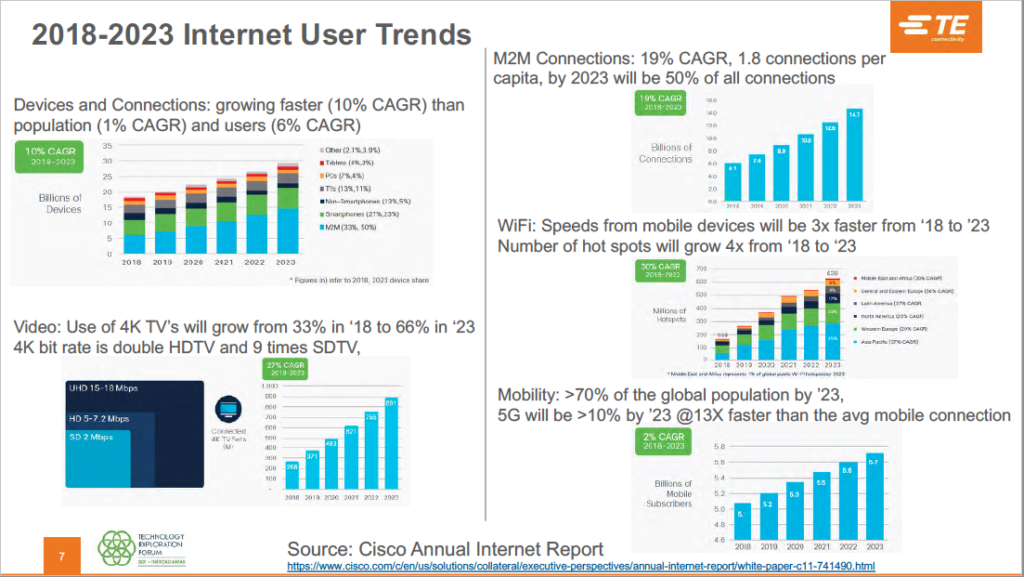 below in part one of a five-part series.
below in part one of a five-part series.
Next-Gen Architectures
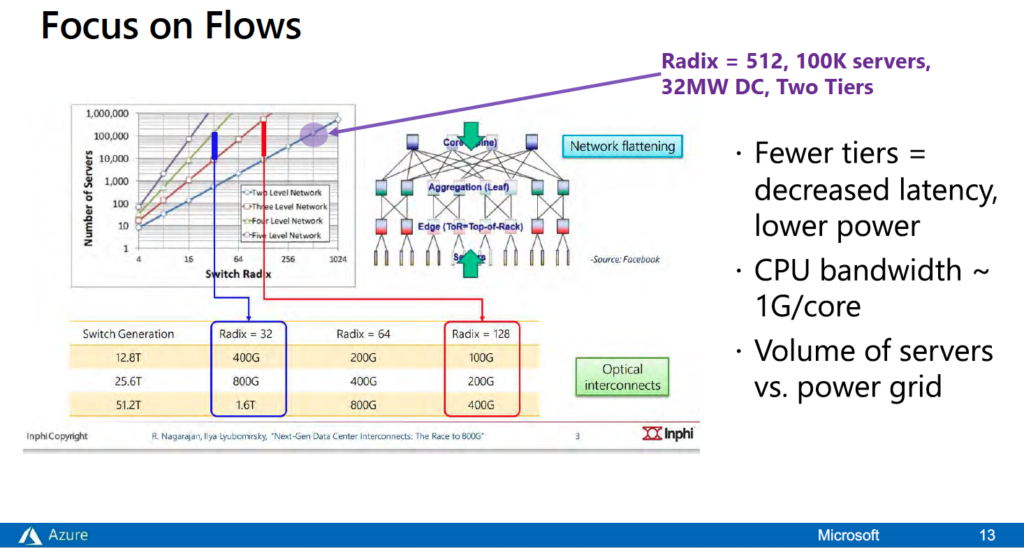
Nathan Tracy: When you talk about the two-tier network, what are some of the compromises that come with that if there’s any?
Brad Booth: It depends. There are always free lunches; it’s just what do you pay for it in the end and whether or not you think that’s free. Where the two-tier network has changed is with the ability to use mesh networks, which just about everybody, including us, is now doing within a lot of their data centers. One of the aspects that we’re not seeing is mesh being done down to the server and I think that’s what’s really going to change. There’s going to be more connectivity showing up here, a lot more optical connectivity and that is going to require new connectors than what we use today. So, yes, you’re correct; the payment is going to be how do we solve the optical connectivity problem. There’s work going on in that area thankfully. It’s not going to be free, but it’ll certainly give us the extension beyond 100 gig per lambda. It’ll give us extensions into whatever we see as being next. Once we make that transition to optics, we’re not so limited anymore by the electrical connectivity.
Nathan Tracy: Line-card based chassis do have the ability to provide very high radix. They can do it in a low latency format. Is that a possible approach?
Brad Booth: Yes, we’ve looked at it. We currently use line-card based chassis in our tier two and tier three network. Our tier three is what sits in our regional gateways. Our tier two is what sits inside our data center and interfaces obviously to our tier ones – and typically for us those are line-card chassis. We are analyzing the use of line-card chassis within the row. The latency in line-card chassis isn’t necessarily vastly better than those in a pizza box. It depends on how much oversubscription you’re dealing with. They do have a well constrained latency understanding because they use a backplane to talk to all these cards and they usually use some type of cell structure. But their latency cannot be as short as if you were to use a monolithic die and have a one-to-one oversubscription. There’s still debate as to what it will really look like in the end, but we are considering both the pizza boxes and the line-cards for our tier one potentially.
 Nathan Tracy: You mentioned 1750 watt. How much of that is electronics? How much of that is cooling the power conversion? Is that just a networking number or does that include more than the networking?
Nathan Tracy: You mentioned 1750 watt. How much of that is electronics? How much of that is cooling the power conversion? Is that just a networking number or does that include more than the networking?
Rob Stone: If you parse out the power that we can deliver to a rack on a sustained basis, that’s where that number comes from and it’s how much each switch is allocated. Currently these switch systems are air cooled, so it includes the fan power for the cooling. But it does not include the air handler systems, the air conditioning and so forth. That’s separate.
Nathan Tracy: You talk about 800G being necessary for your architecture, and I assume that it is a high priority. How long is 800G going to support your architecture before you’re going to come back for more?
Tad Hofmeister: Within the cluster we come out with a new generation roughly every two to three years and it’s driven by generations of switch chips. But we don’t rip everything out. That’s one reason why we need the new generation to be able to interoperate with the old generation fabrics because we keep the generations in service for many years. It varies from generation to generation but it’s on the order of 5-plus years that something will be in the network.
Nathan Tracy: When you talk about links where you’re using coherent, do you ever fully load a switch with the coherent modules? Or is it typically just a few ports?
Tad Hofmeister: Great question. For our metro application and the DCI today we’re using the coherent just for WAN links. So we’re not fully loading it. It’s significantly less – typically fewer than a quarter. As the use case for coherent gets shorter, it transitions from metro to more for campus. There we would anticipate more of the ports needing to work, to be populated with coherent. When we’re driving requirements for the chassis to support an 800G coherent DCO, we really want that chassis to be designed to support fully loaded 800G.
To access TEF21: New Applications Driving Higher Bandwidths on demand, and all of the TEF21 on-demand content, visit the Ethernet Alliance website.


